簡介
提供一個專門用來比較各種NILM演算法的toolkit。 toolkit中包含:
- 針對某些資料集的parsers
- 一些預處理的演算法
- 一組用於描述資料集的統計資料
- 兩個作為參考基準的disaggregation演算法(現有4個)
- 一套精準指標
開發Disaggregation process的動機
- 提供住戶每個裝置耗電的資訊,使住戶可以採取某些策略來進行節電。
- 藉由量化特定裝置的耗損以提供更新裝置的建議。
- 若NILM系統知道各個裝置使用的時間,可以提供一個系統用於通知住戶延遲使用裝置的時間可能減少的電量消耗或碳足跡。(?)
直接比較新方法所面臨的三個難關
- 每個投稿都是以單一的資料集作評估,無法評估是否能普及到新的環境下。且許多研究採用資料集的子集以限制環境、時間、裝置等,更使實驗結果更難重現。
- 各種新方法很少使用相同的演算法作為比較的基準,故無法直覺的比較兩者的好壞。且因這些新方法的缺乏參考實作,也經常導致重複的實作。
- 因許多論文以不同的use case為目的,故其精準度使用不同的performance metric判斷,導致無法直接比較兩份論文。
資料集
- Reference Energy Disaggregation Dataset (REDD)
包含6個環境的aggregate與sub-metered的耗能資料。 - Building-Level fUlly-labeled dataset for Electricity Dis-aggregation (BLUED)
- Smart*
- Pecan Street sample data set
- Household Electricity Survey data set (HES)
- Almanac of Minutely Power dataset (AMPds)
- Indian data for Ambient Water and
Electricity Sensing (iAWE)
- UK Domestic Appliance-Level Electricity data set (UK-DALE)
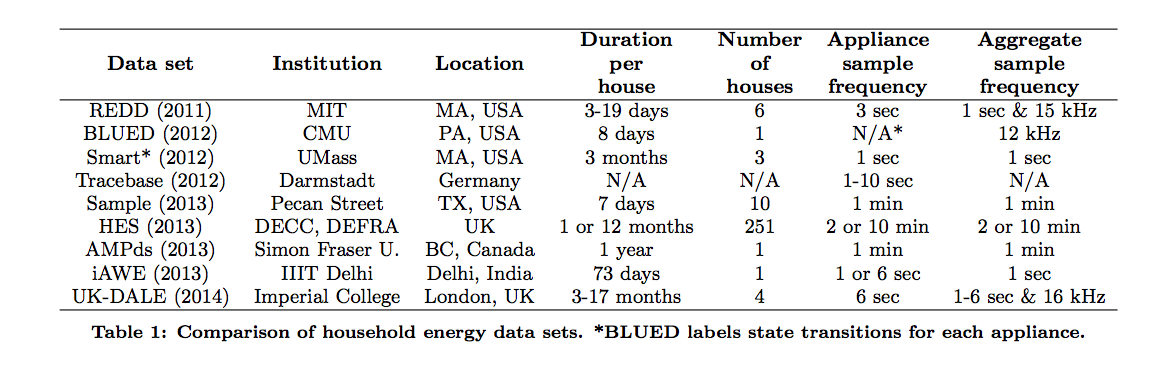 截自NILMTK: An Open Source Toolkit for Non-intrusive Load Monitoring
截自NILMTK: An Open Source Toolkit for Non-intrusive Load Monitoring
很不幸的,由於各個資料集的側重點不同,所以資料格式也有很大的差距,導致各投稿僅使用一個資料集來檢測方法,因此無法研究其結果是否能普及至大量的其他環境。
基準演算法
由於大家對於以什麼演算法作為判斷的基準沒有共識,所以有一堆投稿都是用不同的演算法(e.g. decoupled HMMs, factorial hidden Markov model (FHMM))跟不同的資料集(或同個資料集的子集)來驗證_(:з」∠)_
精準指標
舉例來說,光是使用REDD資料集的disaggregation演算法以energy correctly assigned為名的精準指標就有4種:
- 將每個時段的被錯誤判定的能量經實際能量正規化後,再將所有裝置的值取平均。(當某些時段有巨大錯誤時,會導致負的精準度)
- 將每個時段的被錯誤判定的能量經實際能量正規化後,但不同裝置分開計算。
- 計算整段時間的錯誤而不分成多個時段計算。(由於一個被overestimate的能量可以與在不同的時段被underestimate的能量相抵銷,使其無法表現所有disaggregation的錯誤)
- 報告錯誤而非精準度,每個錯誤的判定會被計算兩次(被overestimate的裝置能量與被underestimate的裝置能量)
NILMTK pipeline
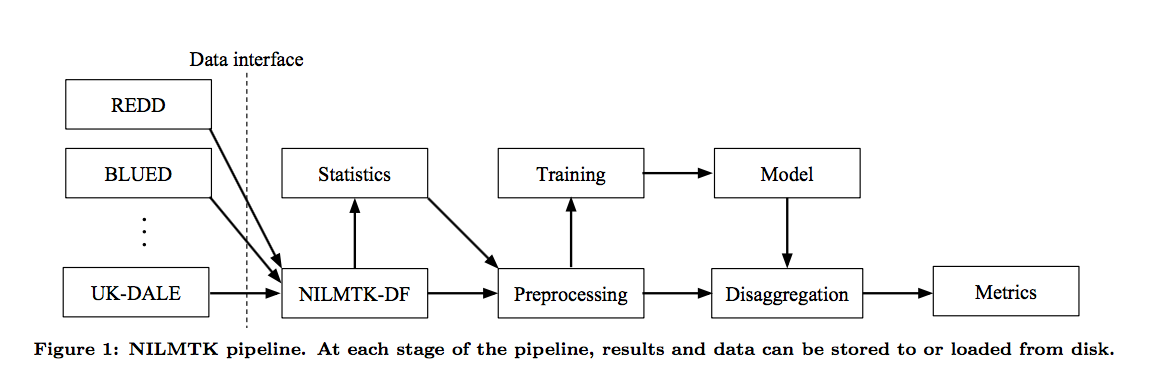 截自NILMTK: An Open Source Toolkit for Non-intrusive Load Monitoring
截自NILMTK: An Open Source Toolkit for Non-intrusive Load Monitoring
Data format
使用NILMTK-DF,一個以REDD的資料格式為啓發設計的資料格式。REDD, Smart*, Pecan Street, iAWE, AMPds, UK-DALE的資料皆可轉換成NILMTK-DF的格式儲存。除了將各種data formet的命名法及格式統一外,NILMTK_DF也允許紀錄豐富的metadata,如房子的地理位置、各個表的參數、表在主要線路上的層級。
* BLUED因缺乏sub-metered的耗能資料,故無法進行轉換 * HES由於時間限制無法轉換
Data Set Diagnostics
由於資料及並非完美的,為幫助研究者在評估方法前先了解各資料集的特徵,NILMTK提供了以下方法幫助診斷一些問題:
Detect gaps: 多數NILM演算法假設每個感測器的波段 (取樣頻率?) 應是連續的,然而當感測器關閉及失常時,此假設會被違背。gap即存在於當任意兩連續的取樣間的時間消耗,大於預先設定的閥值的狀況。
Dropout rate: dropout rate = 總取樣數 / 預期的樣本數 預期的樣本數 = 取樣頻率 * 窗框長
Dropout rate (ignoring gaps): 為量化無線感測器因電波因素導致的取樣遺失率,先將有大gap的資料排除(感測器關閉),並僅以餘留下來的連續訊號計算。
Up-time: 感測器取樣的總時長。 up-time = last timestamp - first timestamp - duration of any gaps
Diagnose: NILMTK提供diagnose函式,以一次檢測所有問題。
Data Set Statistics
不同於diagnostic statistcs,NILMTK也提供了針對裝置進行統計的方法。例如: Proportion of energy sub-metered: 因資料集極少包含所有裝置、線路的子表,此方法可幫助取得子表測量的總能源所佔的比例。在執行統計前,會先把所有子表中的gaps排除,因此所有其他遺失的子表資料理論上都應是由於表或負載(load)被關掉。
Preprocessing of Data Sets
為減弱在Data Set Diagnostics中提到的可能的問題,NILMTK提供了一些預處理的方法:
Downsample: 由於各資料集的取樣頻率各不相同,NILMTK提供了aggregation functions如mean, mode, median來將取樣頻率降至指定頻率。
Voltage normalisation: 由於各國的電壓各不相同,導致計算出來的功耗也會有極大差異,NILMTK使用Hart’s equation提供電壓正規化函式
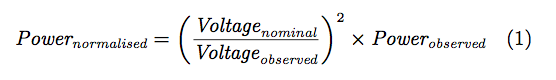
Top-k appliances: 只針對前k個耗能的裝置進行建模,而不對所有裝置建模的優點有3:
- 針對這些裝置的disaggregation提供最多價值。
- 由於這些裝置貢獻了顯著的特徵,使得其他裝置所貢獻的被視為雜訊。
每增加一個裝置的建模都會大幅增加disaggregation task的複雜度。
Interpolating small periods of missing data
Filtering out implausible values (such as readings where observed voltage is more than twice the rated voltage)
Filtering out appliance data when mains data is missing
Training and Disaggregation Algorithms
NILMTK提供了Combinatorial Optimisation (CO)及Factorial hidden Markov model (FHMM)兩種disaggregation演算法的實作,以做為新方法的比較基準。
- Combinatorial Optimisation (CO):
藉由最小化所有預測的裝置能量與觀測出的裝置能量的差值的總和,以找出最適的裝置狀態組合。
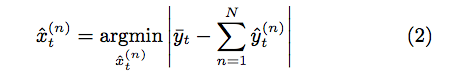
截自NILMTK: An Open Source Toolkit for Non-intrusive Load Monitoring
由於其將每個時間段都視為不同的最優化問題,在每個時間段都要重新進行上述的動作,故其為NP-complete的,時間複雜度為$$O(TK^{n}$$),其中T是時間段的數量,K是裝置的狀態數,n是裝置數量。$$\rightarrow$$只適合對少量裝置建模
- Factorial hidden Markov model (FHMM):
利用HMM模型,將裝置的狀態設為HMM中的隱藏要素。一個FHMM等價於一個狀態為各裝置狀態的組合的HMM,複雜度為$$O(TK^{2N})$$,因複雜度較CO還高,建議使用經過Top-k appliances預處理的資料。 HMM演算法
如FHMM這樣的演算法,需要針對連續的取樣間的關係進行建模,故NILMTK提供了將資料分成連續的集合的方法以供訓練與測試。
An implementation of George Hart's 1985 disaggregation algorithm(新增)
Maximum Likelihood Estimation(新增)
使用了NILMTK的第三方NILM演算法
Appliance Model Import and Export
提供一個模組以建立訓練模型與disaggregation模型間的介面。將訓練模型得出的結果輸出至json再輸入至disaggregation模型。
Accuracy Metrics
提供了以下的Accuracy Metrics:
- Error in total energy assigned
- Fraction of total energy assigned correctly
- Normalised error in assigned power
- RMS error in assigned power
- Confusion matrix
- True positives, False positives, False negatives, True negatives
- True/False positive rate
- Precision, Recall
- F-score
- Hamming loss
實際測試結果
- 下圖為各資料集經NILMTK提供的方法分析的結果,從AMPds及Pecan Street的0 dropout rate與100%的up time可以發現其使用了更堅固的紀錄平台。
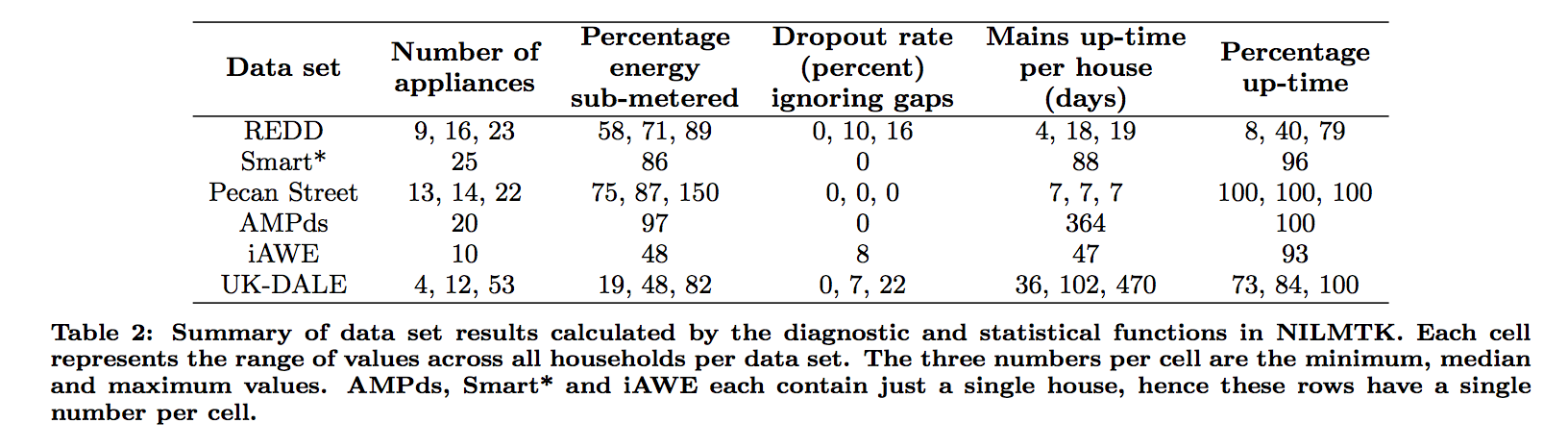
截自NILMTK: An Open Source Toolkit for Non-intrusive Load Monitoring - 配合環境與時間資訊與資料的關係,可能對分析有很大的幫助。
- 使用FHMM較之CO在FTE, NEP, F-score中普遍有較好的結果(CO對aggregate load的細小變動很敏感),但需花更多的時間做訓練及disaggregate。